Method
연구 내용
시스템 모델
네트워크 및 채널 모델
다중 셀 5G MIMO 환경을 가정하고, 이동 사용자와 셀 간 간섭이 동시에 존재하는 시나리오를 구성했다. 채널은 3GPP 기반 모델과 불완전한 CSIT 조건을 반영해 실제적인 전송 환경에 가깝게 설정했다. 이를 통해 제안 기법이 이상적인 환경이 아니라, 실제 운용에서 빈번하게 나타나는 채널 불확실성과 간섭 상황에서도 유효한지 확인하고자 했다.
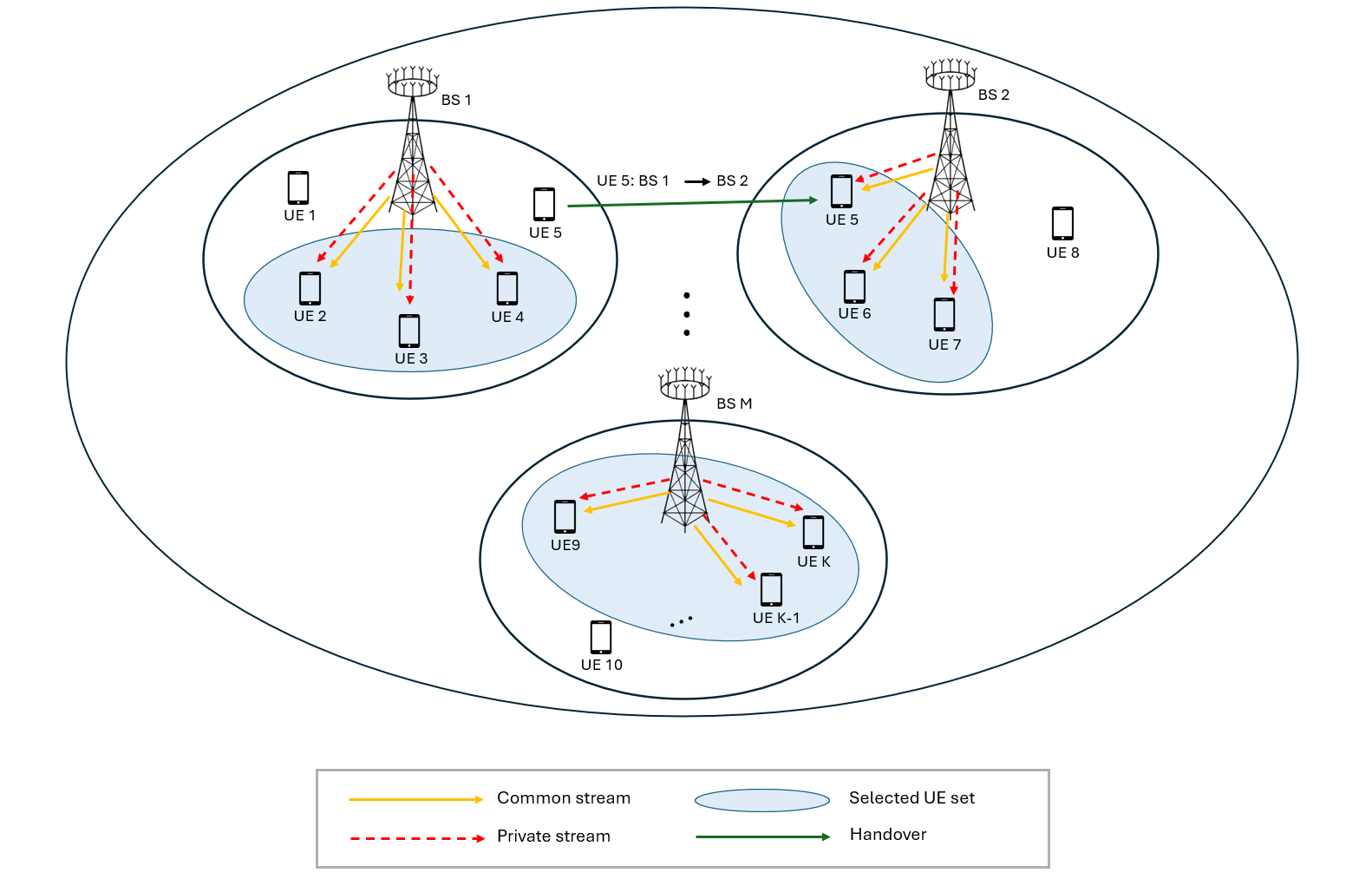
저복잡도 사용자 선택 기반 RSMA 전송 모델
제안 기법은 모든 사용자를 동시에 최적화하기보다, 사용자 선택 단계에서 PF 지표와 채널 공간 직교성을 함께 고려한다. 이를 통해 공통 스트림 복호 부담을 줄이면서도 자원 집중으로 인한 성능 왜곡을 완화한다. 즉, RSMA의 장점은 유지하면서도 사용자 수가 많아질수록 커지는 계산 복잡도와 스케줄링 부담을 함께 줄이는 방향으로 설계했다.
A3 기반 핸드오버 모델
네트워크 계층에서는 A3 기반 핸드오버 규칙과 CIO를 이용해 접속 셀을 조정한다. 이 과정은 사용자 분산과 실패 핸드오버 억제를 동시에 고려하는 제어 변수로 사용된다. 특히 CIO 조정은 셀 경계 부근 사용자의 재접속 패턴에 직접적인 영향을 주므로, 단순 부하 분산이 아니라 연결 안정성 측면에서도 중요한 역할을 한다.
처리량 및 부하 모델
성능 평가는 단순 전송률이 아니라 사용자 처리량과 셀 간 부하 편차를 함께 본다. 이를 통해 전송 효율과 네트워크 균형을 동시에 반영하는 목적 구성이 가능해진다. 총 처리량은 네트워크 전체 효율을 나타내고, 부하 표준편차는 특정 셀로의 쏠림 정도를 보여주기 때문에 두 지표를 함께 봐야 실제 운용 관점의 성능을 평가할 수 있다.
문제 정식화
최종적으로 본 연구는 처리량을 높이면서도 부하 불균형을 줄이는 공동 최적화 문제를 정의한다. 즉, 개별 링크 성능보다 네트워크 전체 자원 사용의 균형을 함께 고려하는 형태다. 이 목적 함수는 특정 지표 하나만 극대화하는 대신, 실제 통신망 운용에서 요구되는 효율성과 안정성의 절충점을 찾도록 설계됐다.
TD-MPC2 기반 자원 최적화 프레임워크
멀티 타임스케일 교차 계층 제어 구조
RSMA 분할 비율은 빠르게 조정하고, CIO는 상대적으로 느린 주기로 갱신하는 멀티 타임스케일 구조를 사용했다. 이는 두 제어 변수의 시간적 특성을 분리해 학습 안정성과 제어 효율을 함께 확보하기 위한 구성이다. 실제로 전송 파라미터와 핸드오버 파라미터는 반응해야 하는 시간 규모가 다르기 때문에, 이를 동일 주기로 다루면 학습이 불안정해지거나 제어가 과도해질 수 있다.
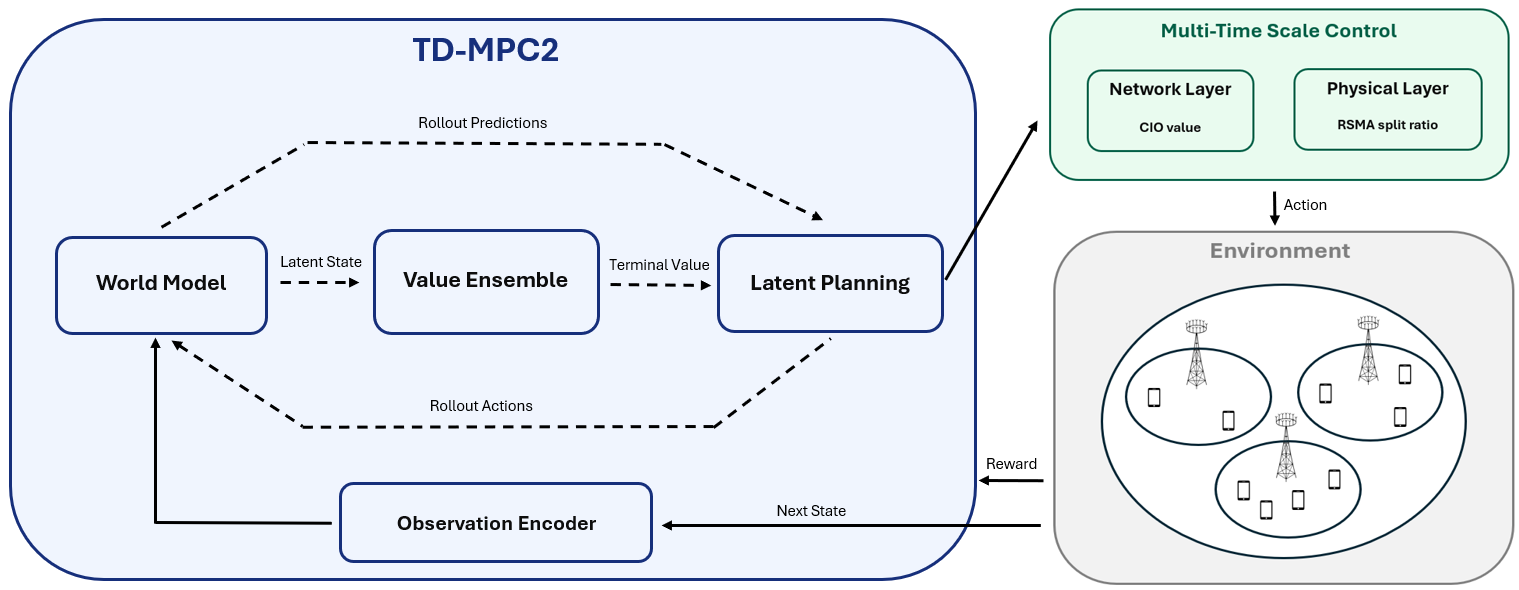
MDP 정식화
멀티 타임스케일 네트워크 제어 문제는 중앙집중형 에이전트가 전역 상태를 관측하고, 다중 셀의 제어 변수를 동시에 결정하는 MDP로 구성된다. 이 정식화는 네트워크 상태 변화, 행동 선택, 보상 관측의 관계를 일관된 학습 문제로 바꾸기 위한 단계이며, 이후 TD-MPC2가 계획 기반으로 정책을 찾을 수 있는 기반이 된다.
상태 공간
상태는 셀 부하, 부하 변화율, 큐 상태, 분할 비율, CIO, 사용자 분포를 포함하는 전역 벡터로 정의한다. 즉, 물리 계층과 네트워크 계층에서 의사결정에 필요한 핵심 정보만 압축해 하나의 관측 상태로 구성했다.
행동 공간
행동은 각 셀의 RSMA 분할 비율과 CIO를 결합한 벡터로 구성되며, 두 계층 제어를 동시에 반영한다. 이를 통해 전송 측 제어와 셀 선택 유도 제어가 분리된 두 문제가 아니라 하나의 협력적 정책으로 작동하도록 만들었다.
보상 함수
보상은 처리량과 부하 균형을 함께 반영해 두 성능 지표의 절충점을 찾도록 설계했다. 보상 설계는 에이전트가 특정 셀 성능이나 특정 사용자의 순간 이득에 치우치지 않도록 하는 핵심 요소다.
TD-MPC2 알고리즘
TD-MPC2는 잠재 공간에서 환경의 전이를 예측하고, 계획 기반 추론을 통해 장기적인 제어 성능을 확보하는 모델 기반 강화학습 구조다. 본 연구에서는 표본 효율과 수렴 안정성을 함께 확보하기 위해 TD-MPC2를 채택했으며, 복잡한 네트워크 제어 문제에 대해 비교적 적은 상호작용으로도 유효한 정책을 학습하도록 했다.
월드 모델
관측 상태를 저차원 잠재 표현으로 사상한 뒤, 다음 잠재 상태와 보상을 예측하는 세계 모델을 학습한다. 이 잠재 모델은 고차원 원시 상태를 직접 다루는 부담을 줄이고, 계획 단계에서 더 빠른 시뮬레이션을 가능하게 한다.
잠재 공간 기반 계획
학습된 세계 모델을 이용해 유한 시간 구간의 미래 보상을 예측하고, 기대 누적 할인 보상을 최대화하는 방향으로 행동을 선택한다. 이는 현재 시점의 즉각적인 이득보다, 몇 단계 이후의 부하 이동과 처리량 변화를 함께 고려한 정책 선택을 가능하게 한다.
네트워크 최적화 및 파라미터 갱신
학습 과정에서는 일관성 손실, 보상 손실, 가치 손실을 함께 최소화하며 정책과 가치 추정을 동시에 갱신한다. 이러한 다중 손실 구조는 동적 모델 정확도와 정책 품질을 동시에 유지하는 데 중요하며, 결과적으로 더 안정적인 온라인 제어 성능으로 이어진다.