Experiments
실험 방법 및 결과
실험 방법
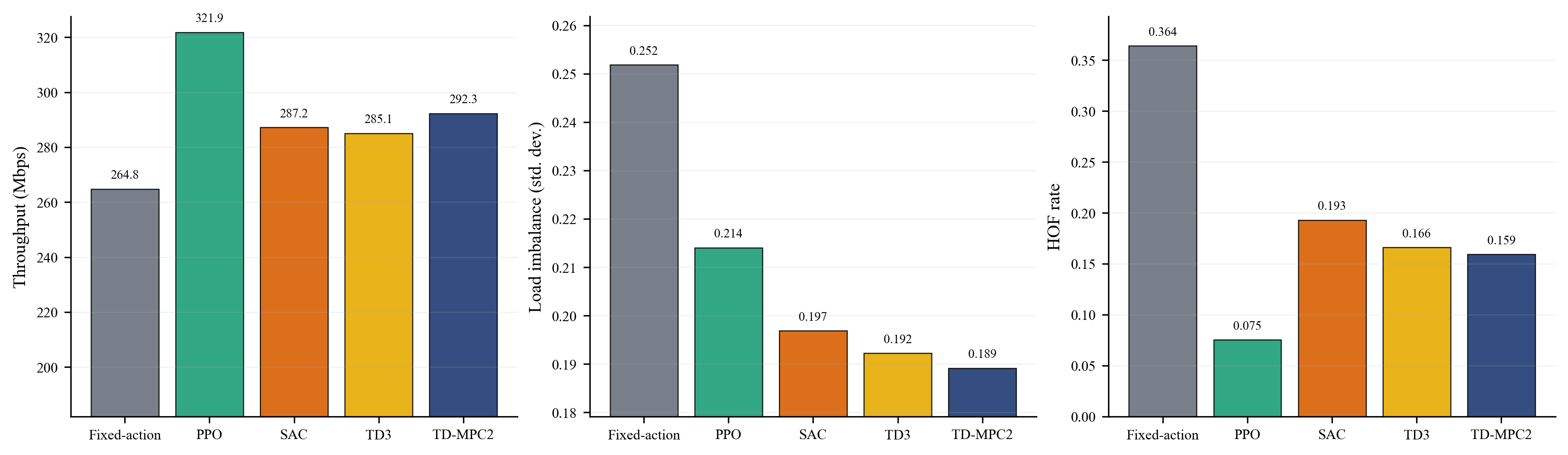
실험은 3GPP UMi Street-Canyon 기반의 다중 셀 환경에서 수행했으며, 5개 기지국과 60명의 사용자를 배치했다. 제안 기법은 Fixed-action, PPO, SAC, TD3와 비교해 학습 안정성과 제어 성능을 함께 확인했다. 비교 기준은 단순 처리량이 아니라 부하 균형과 핸드오버 실패율까지 포함해, 실제 네트워크 운용 관점에서의 장단점을 함께 보도록 구성했다.
아래 표는 시뮬레이션 환경과 TD-MPC2 설정을 정리한 것으로, 네트워크 규모, 채널 조건, 트래픽 패턴, 계획 기반 강화학습의 주요 하이퍼파라미터를 함께 제시한다.
| Category | Parameter | Value |
|---|---|---|
| Network | Deployment area | 800 m x 800 m |
| Inter-site distance (ISD) | 250 m | |
| Number of Base stations / Total Users | 5 / 60 | |
| Base station transmit power / Antenna gain | 33 dBm / 5 dBi | |
| Antenna configuration | 4 x 1 | |
| Channel | Carrier frequency / Bandwidth | 3.5 GHz / 100 MHz |
| Pathloss / Shadowing | TR 38.901 NLOS / 7.82 dB | |
| CSIT error factor | 0.1 | |
| Hysteresis / Time-to-Trigger | 3 dB / 320 ms | |
| Traffic | Mobility / Traffic model | Street-grid / Constant bit rate |
| Data rate per User | 8 Mbps | |
| User speed groups / Count | {0.5-1.5, 1.5-3.0, 4.0-8.0} m/s / 20 each |
| Category | Hyperparameter | Value |
|---|---|---|
| Learning | Batch size | 64 |
| Learning rate | 5.4041e-4 | |
| Discount factor | 0.99 | |
| Max gradient norm | 20 | |
| Architecture | Encoder dim / layers | 256 / 2 |
| Latent dim | 256 | |
| Value nets / dropout | 5 / 0.01 | |
| SimNorm dim | 8 | |
| Number of bins (HL-Gauss) | 101 | |
| Planning | Horizon | 5 |
| Iterations | 4 | |
| Samples | 256 | |
| Elites | 64 | |
| Objective | Consistency loss scale | 20 |
| Reward / Value loss scale | 0.1 / 0.1 |
실험 결과
시스템 성능 비교
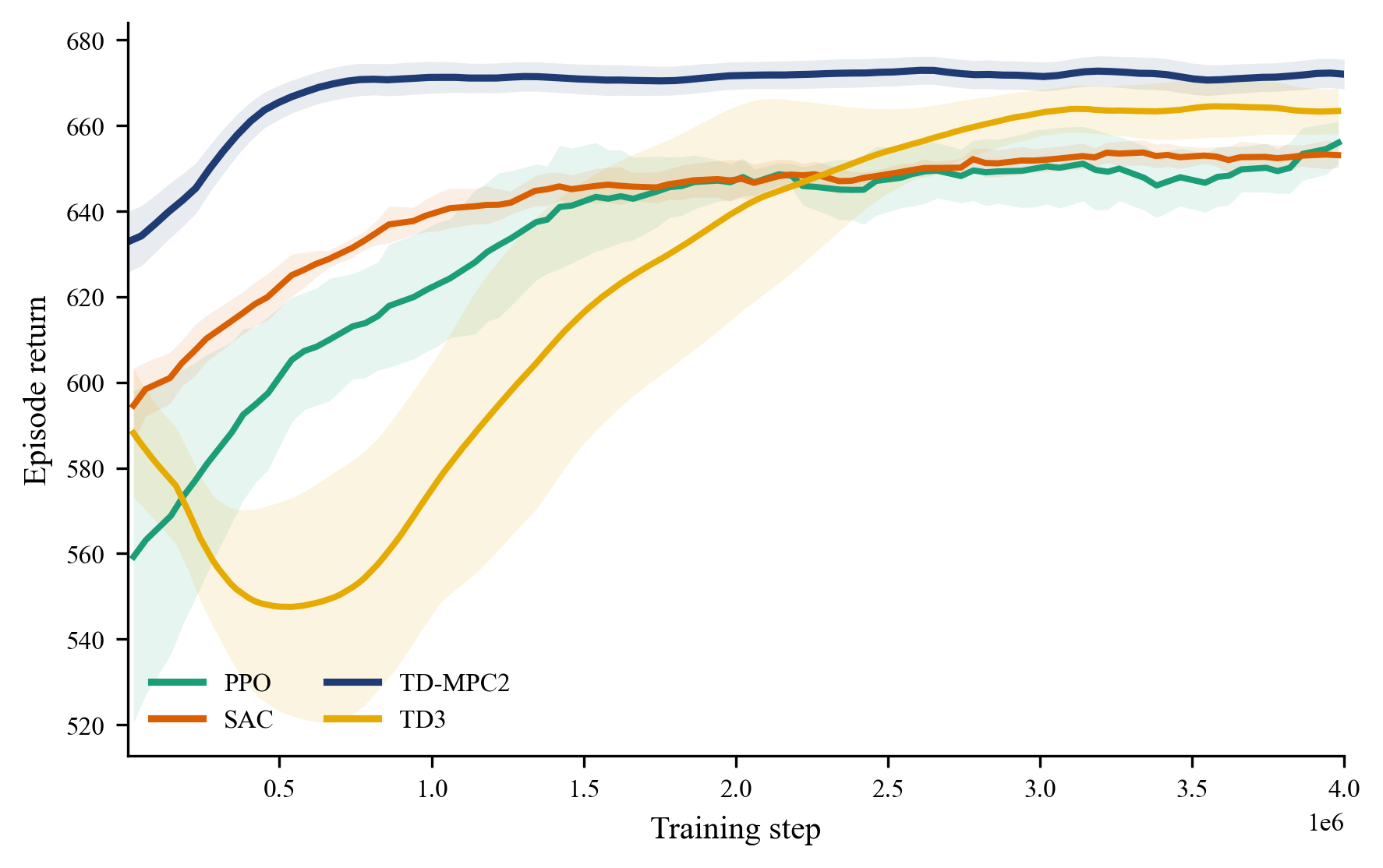
제안 기법은 학습 수렴 속도와 최종 성능 모두에서 안정적인 결과를 보였고, 특히 처리량 향상뿐 아니라 부하 불균형과 핸드오버 실패율도 함께 줄이는 경향을 확인했다. 이는 단일 지표만 개선한 것이 아니라, 네트워크 효율과 연결 안정성을 동시에 확보했다는 점에서 의미가 있다.
학습 과정에서는 비교 기법보다 빠르게 높은 성능 구간에 도달했고, 최종 수렴 이후에도 성능 변동 폭이 크지 않았다. 결과적으로 제안 기법은 고정 정책이나 기존 model-free 강화학습 대비 더 균형 잡힌 전역 제어 전략을 형성했다.
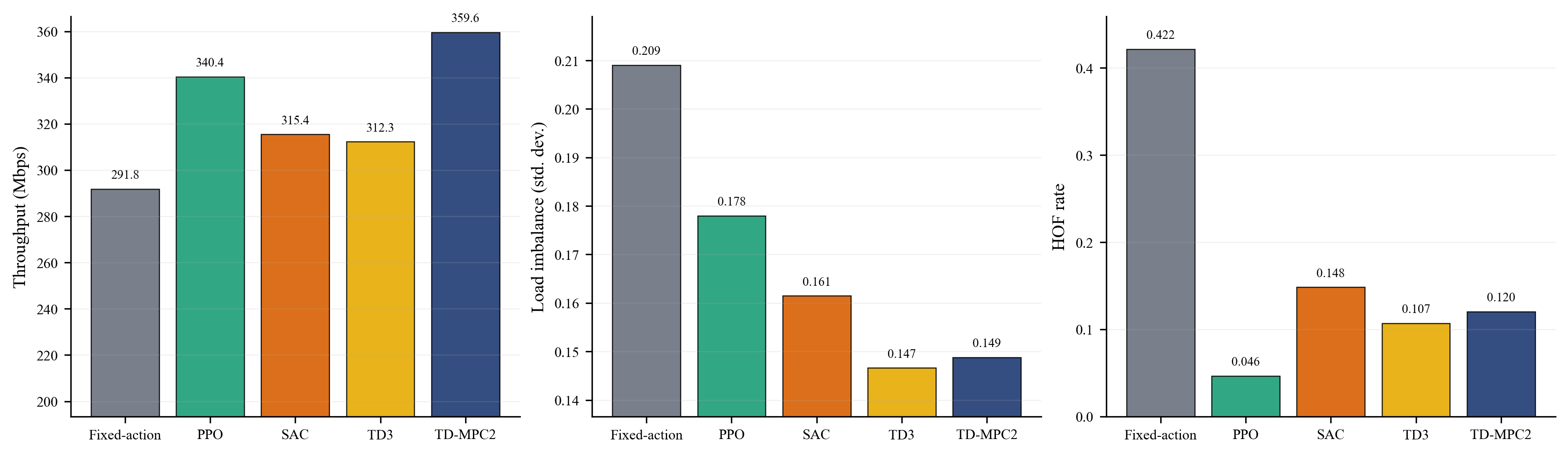
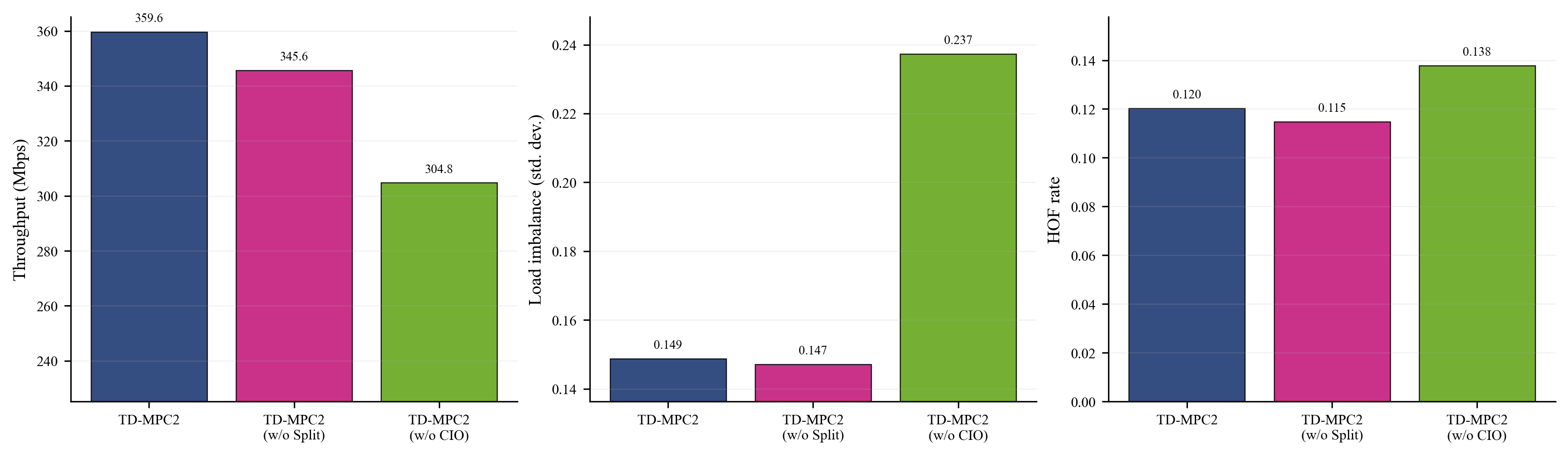
제안 기법의 효용성
RSMA 분할 비율만 제어하거나 CIO만 제어하는 경우와 비교했을 때, 두 제어를 함께 사용하는 구성이 가장 균형 잡힌 성능을 보였다. 이는 전송 구조와 핸드오버 제어를 분리하지 않고 공동 최적화하는 접근이 중요하다는 점을 보여준다.
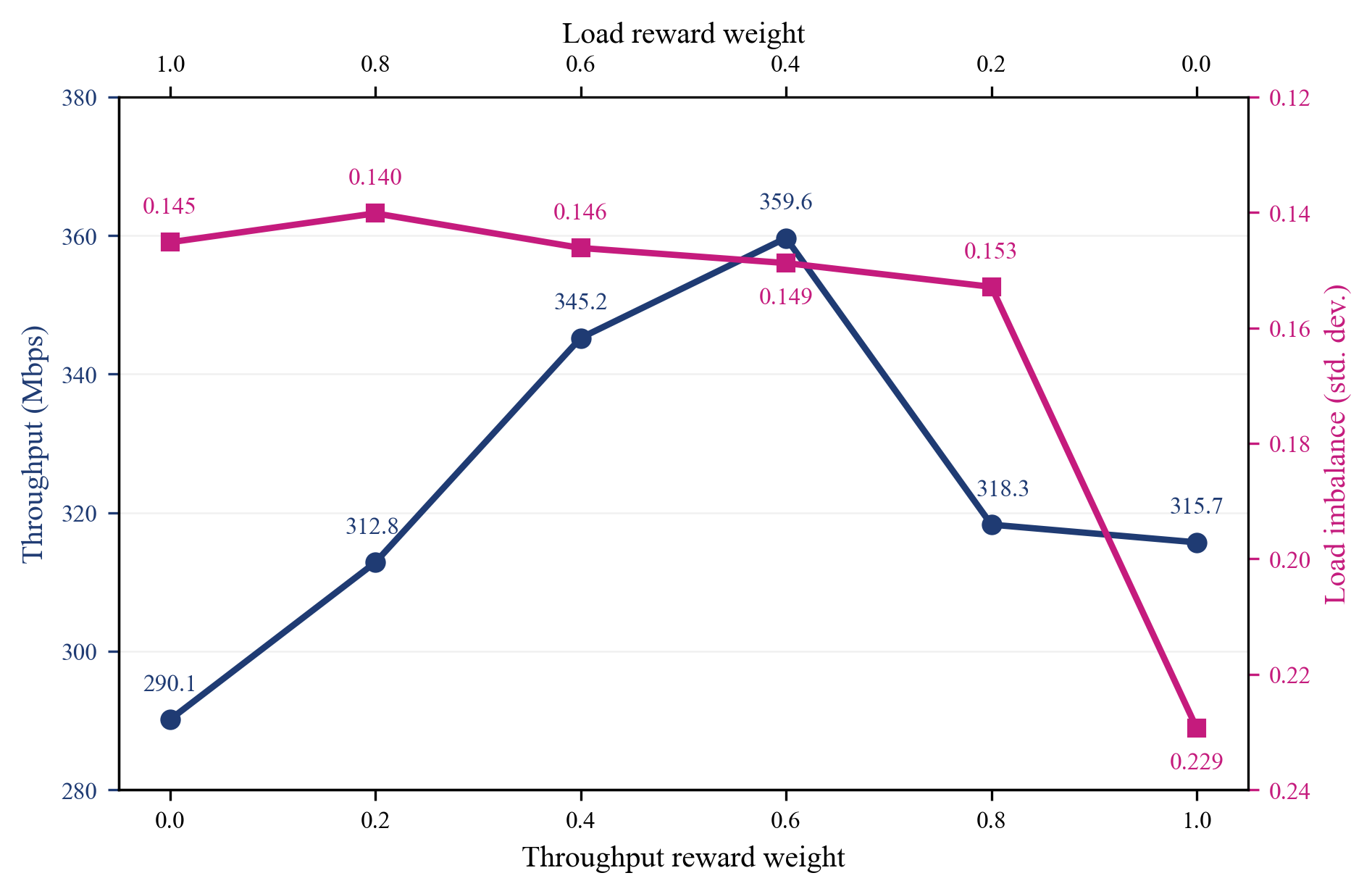
보상 가중치를 바꾼 실험에서도 처리량과 부하 분산 사이의 상충관계가 확인됐으며, 본 연구의 설정은 두 지표를 함께 고려하는 절충점으로 작동했다. 즉, 어느 한 축을 극단적으로 밀어붙이기보다 실제 운용에 적합한 균형점을 학습하도록 보상 설계가 기능했음을 확인할 수 있다.
이 분석은 제안 기법의 성능 향상이 단순히 더 복잡한 알고리즘을 썼기 때문이 아니라, RSMA 제어와 부하 분산 제어를 함께 설계한 구조적 이점에서 나온 결과임을 뒷받침한다.
이질 트래픽 환경 일반화 성능
학습 환경과 다른 트래픽 조건에서도 제안 기법은 비교적 안정적인 성능을 유지했다. 이는 특정 시나리오에만 맞춰진 정책이 아니라, 환경 변화에도 대응 가능한 제어 전략임을 시사한다. 특히 CBR과 ON/OFF, heavy-tailed ON/OFF가 혼재된 상황에서도 성능 저하가 제한적이었다는 점은 실용적인 장점이다.
다시 말해 제안 기법은 훈련 시 보지 못한 트래픽 혼합에서도 전송 효율과 부하 분산 간의 균형을 비교적 잘 유지했으며, 실제 서비스 환경에서 예상되는 트래픽 변동성에 대해 일정 수준의 견고함을 보여줬다.
| Parameter | Value |
|---|---|
| Number of User | 60 |
| Mobility Speed | 5.0 m/s |
| Group 1 Traffic (20 Users) | Constant bit rate, 8 Mbps |
| Group 2 Traffic (20 Users) | Heavy-tailed ON/OFF, Mean 8 Mbps |
| Group 3 Traffic (20 Users) | ON/OFF, Mean 8 Mbps |
결론 및 토의
본 연구는 RSMA 기반 전송 제어와 CIO 기반 부하 분산을 공동 최적화하는 프레임워크를 제안했고, 모델 기반 강화학습을 통해 처리량과 안정성을 함께 개선할 수 있음을 보였다.
실험 결과는 전송 효율, 부하 균형, 핸드오버 안정성이 서로 분리된 문제가 아니라는 점을 보여주며, 교차 계층 제어와 계획 기반 강화학습의 결합이 실제 네트워크 최적화에 유효할 수 있음을 시사한다.
향후에는 더 큰 네트워크 규모, 다양한 시간 척도 제어, 에너지 효율과 QoS 제약까지 포함하는 방향으로 확장할 수 있다.